
En este segundo artículo nos centraremos en algunas de estas nuevas funcionalidades que se han introducido en ABAP. Si te perdiste el primero puedes leerlo aquí.
Programación orientada a objetos
En programación orientada a objetos, un proceso DOWNCAST es aquel en el un objeto de referencia tipificada hereda el tipo de un objeto más específico. Un proceso UPCAST es lo contrario, un objeto especifico se convierte en un objeto genérico.
Para este caso queremos una definición de una estructura, obteniendo todos los elementos de esa estructura. Para ello, nos ayudaremos de la clase «CL_ABAP_TYPEDESCR», que es una subclase de la clase «CL_ABAP_STRUCTDESCR», por lo que necesitaremos servirnos del DOWNCAST para convertir la instancia de la clase padre «CL_ABAP_STRUCTDESCR» en la instancia de la subclase «CL_ABAP_TYPEDESCR».

En las versiones recientes podremos ejecutar todas estas sentencias en una sola línea empleando para ello el comando «CAST», y de esta forma nos estaríamos ahorrando un paso intermedio y la declaración de «lo_structure_comp».

ABAP SQL:
En primer lugar, vamos a diferenciar entre Open SQL y Native SQL:
- Open SQL te permite acceder a las tablas de la base de datos declaradas en el diccionario ABAP independientemente de la plataforma de base de datos que utilice el sistema R/3.
- Con native SQL podemos utilizar sentencias SQL de un programa ABAP y utilizar tablas de base de datos que no están administradas por el diccionario ABAP. Para emplear estas sentencias debemos emplear el comando EXEC SQL y ENDEXEC al finalizar.
CASE and colums:
A partir de la versión 7.4, podemos emplear “CASE” en selecciones Open SQL. En el siguiente ejemplo seleccionamos 2 campos (PERNR y BEGDA) y un tercero que se define con el alias de BKRS_TEXT, que tomará el valor de “Mutilva”, “France” o “No Company” en función del valor que contenga el campo “BUKRS” correspondiente a esa entrada. Podemos ver cómo nos permite la posibilidad de crear la estructura “ls_0001” in situ.
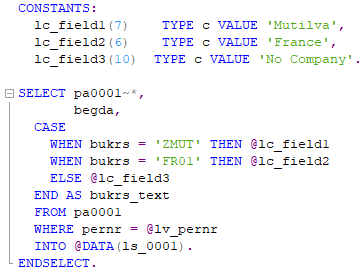
Como resultado obtendremos una estructura ‘ls_0001’ que a su vez contiene la estructura del infotipo ‘0001’, en la que, al ser el campo ‘BUKRS’ = ZMUT, nuestro campo ‘bukrs_text’ adquiere el valor de la constante ‘Mutilva’.
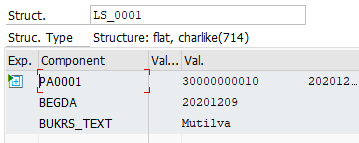
GROUP BY
La idea principal es, como su propio nombre indica, agrupar los datos que necesitamos, evitando un loop anidado. El primer ‘Loop’ es donde usamos el campo clave por el que vamos a agrupar:
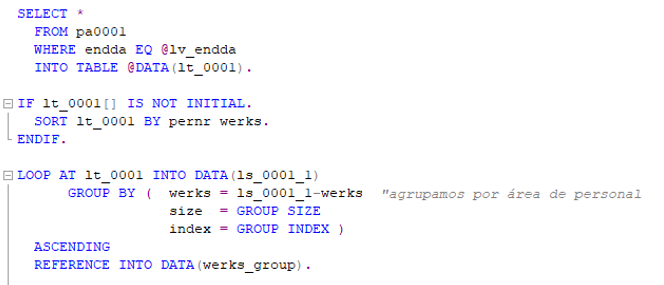
En el segundo ‘Loop’ es donde, recorriendo los diferentes grupos que hemos formado, añadimos la lógica:
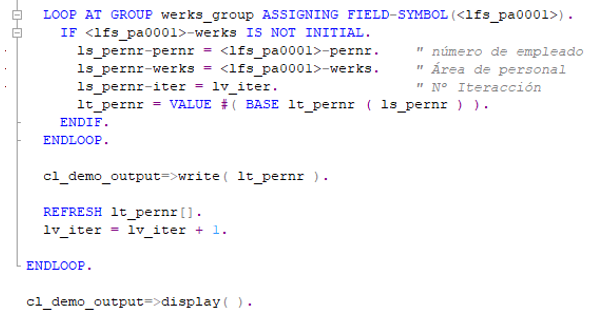
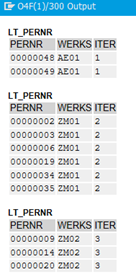
A continuación, podemos ver las distintas iteraciones. Hemos agrupado nuestra tabla interna por el campo ‘Werks’. Por lo que en cada una de esas iteraciones podemos realizar la lógica que deseamos, como puede ser mandar un mail a una serie de destinatarios, agrupar esas entradas en otra tabla interna, etc.
Esperamos que este artículo te haya resultado interesante. Si tienes alguna duda, no dudes en ponerte en contacto con nuestro equipo de HXM.



