
Introducción
En títulos anteriores de Buenas Prácticas, vimos Tips para entender y mejorar la forma de programar. En este nuevo título se aprenderá que prácticas no se deberían hacer y así seguir puliendo las bases de una buena programación. No se debe realizar un código rápido y chapucero. Tener un código limpio ayuda a evitar problemas en casuísticas no esperadas, ayuda a no tener que rehacer trabajo innecesario y a evitar sentencias obsoletas cuando SAP se actualice.
Comentarios
Muchas veces pecamos de un exceso de comentarios o unos comentarios poco explicativos. Al realizarlos intentaremos explicar con el mínimo de palabras posibles la lógica, orientado para entender funcionalmente las sentencias y donde añadiremos un comentario adicional en casos excepcionales por la dificultad técnica y así poder entender el desarrollo.
Entonces, intentaremos evitar comentarios obvios como:
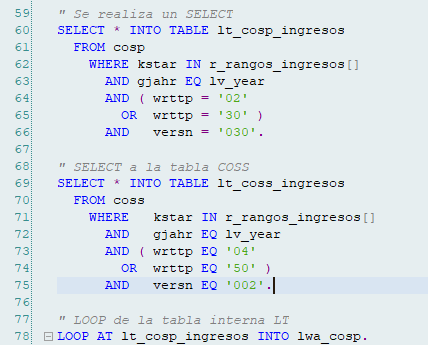
Mejorarían considerablemente cambiando el planteamiento:
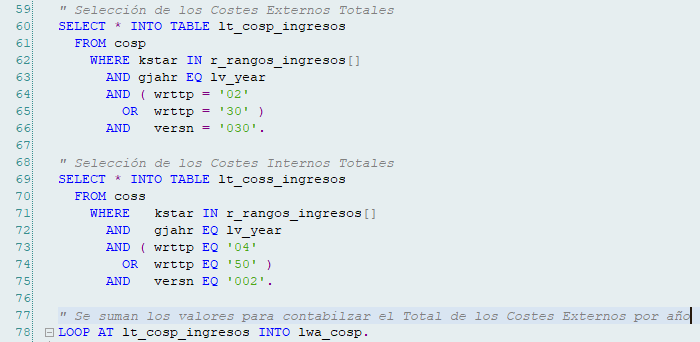
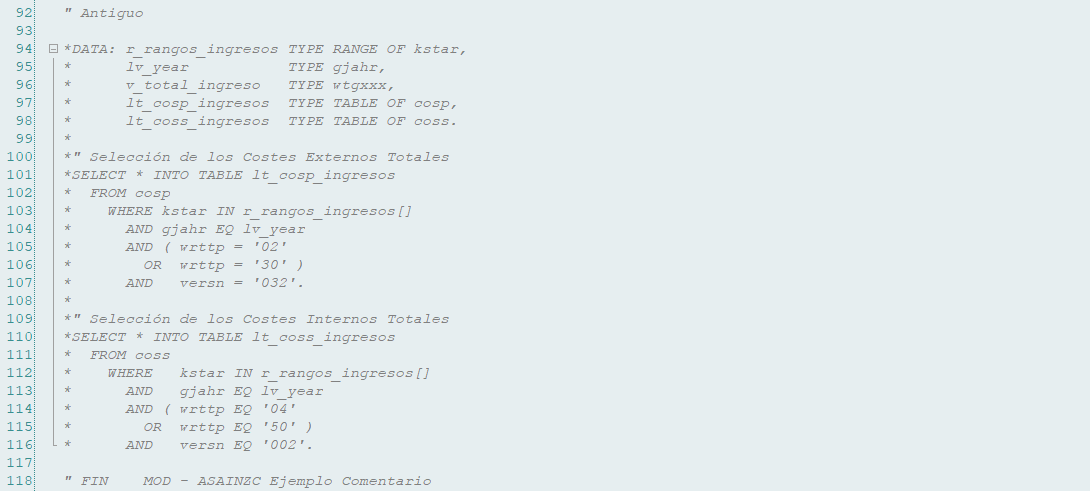
Otra cosa que se debe evitar es una excesiva cantidad de comentarios, nos suele suceder sobre todo al comentar las modificaciones en un código ya existente en producción.
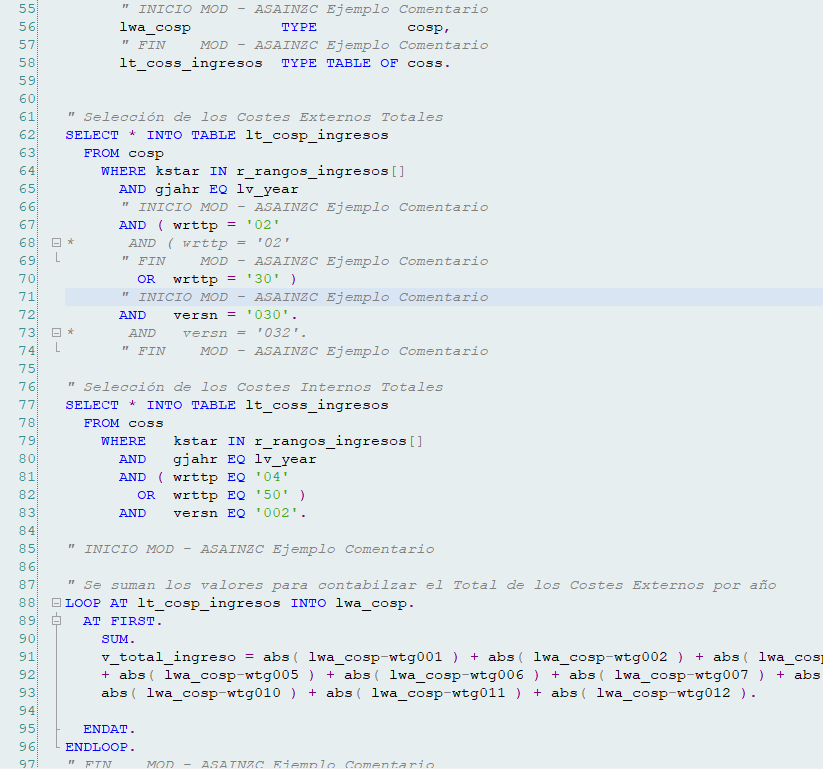
Es mucho mejor realizar el cambio en limpio, colocando un comentario adicional con el motivo del cambio y si es necesario en la línea donde se ha realizado para aclararlo más aún.
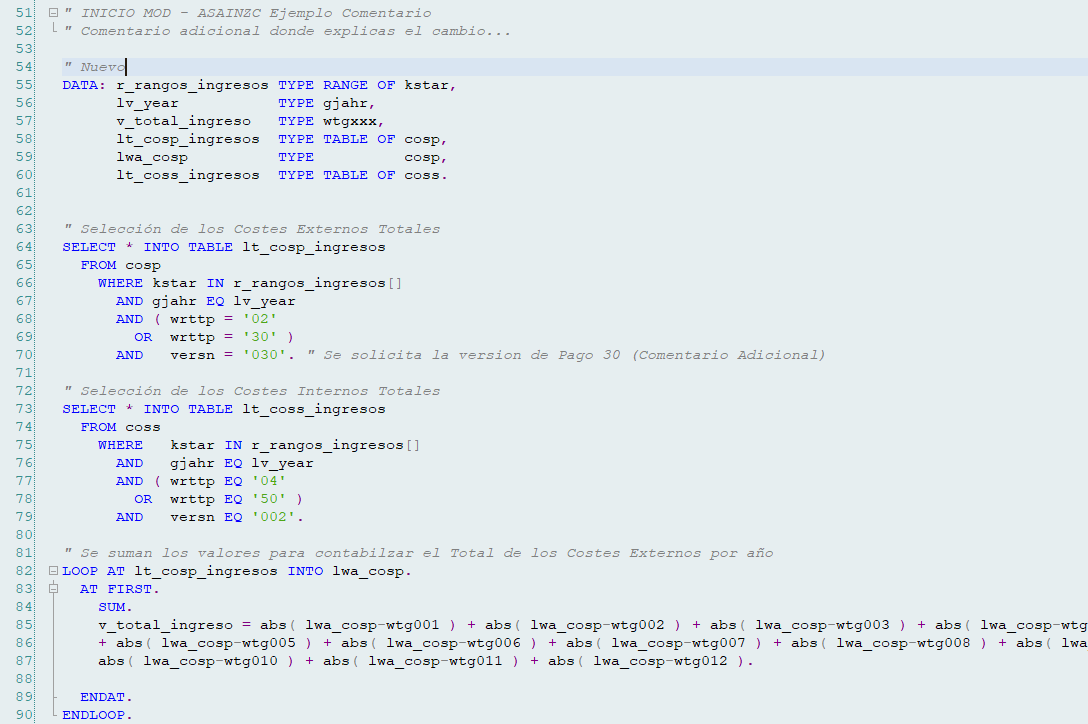
Y dejar el código antiguo marcado para poder revisarlo en caso de que el cambio no sea correcto.
Sentencias que NO debemos usar
Hay una serie de sentencias que por su uso no deberíamos usar o no en ese lugar. Hoy vamos a ver una serie de acciones que no deberíamos usar.
Sentencias Dentro de un Bucle
Cuando se realiza código en un bucle, ya sea un “LOOP” o cualquier sentencia que te permita repetir “n” veces un fragmento de código hay que tener mucho cuidado, se debe intentar evitar ciertas acciones para no caer en posibles errores que puedan resultar graves a pesar de que el código funcione perfectamente.
Inicializa Datos
Como se mostró en el anterior título, inicializar datos es muy importante, no solo se debe resaltar la nomenclatura y los nombres claros al crearlos, sino también es importante donde se deben crear. Inicializar datos dentro de un bucle hace que ese dato se esté creando tantas veces como vueltas realice el bucle, esto puede desencadenar que esa inicialización no sea correcta y que el código falle a pesar de que el resto de las lógicas funcionen correctamente.
Bucles Dentro de Bucles
Un bucle dentro del bucle no es mortal, pero es muy peligroso ya que encadenarlos puede generar un Bucle Infinito si entre ellos se van retroalimentando.
También ralentiza mucho la ejecución, el bucle inferior se ejecuta tantas veces como vueltas tenga multiplicado por el número de vueltas que realiza el superior. Si el inferior tiene 5 vueltas y el superior 10. Cada línea de código situada en el bucle inferior se puede llegar a ejecutar hasta 50 veces. Ahora imaginaros el planteamiento si se trataran de tablas con miles o incluso millones de registros.
Existen formas de poder evitarlo en ciertos casos. Una de ellas es evitar “LOOPs” dentro de un bucle recuperando el valor individual antes de entrar, también se pueden tratar las tablas por separado fuera del encadenamiento de bucles y por último podemos ayudarnos de sentencias como “READ TABLE” para obtener los registros que únicamente sean necesarios.
Cuando no es evitable mínimo se debe mínimo filtrar las tablas o reducirlas lo máximo posible y realizar comprobaciones para poder salir del bucle infinito gracias a sentencias como “EXIT”.
Acceso a Bases de Datos
Solo el propio hecho de acceder a las Bases de Datos ya ralentiza el código, es inevitable, aunque basándonos en esta premisa se puede intentar ralentizarlo lo menos posible.
Bucles
En base a la premisa, acceder muchas veces a una misma tabla lo único que puede hacer es ralentizar mucho la ejecución. Es preferible recuperar una cantidad de datos mayor fuera del bucle y luego filtrarlos en base a la necesidad que apuntar muchas veces a una misma tabla (Tanto dentro de un bucle como fuera del mismo).
Acceso por Clave
Cuando se accede a través de los campos claves de una tabla permites que los filtros accedan a la parte más rápida de la memoria, por lo tanto, hay que intentar evitar filtros por campos que no sean claves, mínimo se debe acceder a través de uno de ellos. En caso de que no sea posible, se realizara a través de los unívocos.
Con esto no se quiere decir que no se filtre por los campos NO clave o NO unívocos, sino que además de esos filtros que necesites para la lógica se deben añadir filtros por campos clave o unívocos.
Asterisco
El “SELECT *” es la forma más sencilla de acceder a las Bases de Datos, se debe evitar usar por dos motivos, el primero que con la actualización HANA va a pasar a estar obsoleto.
El segundo es porque si no necesitas todos los campos, estas trayendo información adicional que si no la incluyes en el tipo de la Estructura/Tabla destino hará que el resto de los campos se descuadren.
Sí hay una forma de evitarlo, y es gracias a la sentencia “INTO CORRESPONDING FIELDS”, aunque lamentándolo mucho, esta sentencia está obsoleta por lo que es una sentencia más a evitar.
Sentencias Y Acciones Obsoletas
Por último, SAP en sus actualizaciones y ayudas (F1), va indicando que sentencias son obsoletas y es recomendable evitar cara a la actualización HANA.
A lo largo de este aprendizaje ya habéis podido observar algún ejemplo, otros ejemplos serian la sentencia “LIKE” que es sustituida por “TYPE” en gran parte de las lógicas, y “EXPORT TO DATASET” que es sustituida por “TRANSFER”.
Conclusión
Las buenas prácticas en la programación son importantes, aunque programar sin malas prácticas es la clave. Recuerda que puedes dejar tus dudas en los comentarios o ponerte en contacto con nosotros.



