
En este artículo analizaremos la sentencia PROVIDE de SAP, tratando de dar una clara y breve explicación para, después, poder ver una aplicación directa sobre el área de RRHH. Antes de entrar en la parte técnica, la sentencia principalmente sirve para recoger uno a uno los diferentes intervalos numéricos o temporales entrelazados que definan dos campos numéricos de dos o más tablas.
La sentencia, por lo tanto, se implementa haciendo uso del siguiente código:
PROVIDE FIELDS {*|{comp1 comp2 …}}
FROM itab1 INTO wa1 VALID flag1
BOUNDS intliml1 AND intlimu1
[WHERE log_exp1]
FIELDS {*|{comp1 comp2 …}}
FROM itab2 INTO wa2 VALID flag2
BOUNDS intliml2 AND intlimu2
[WHERE log_exp2]
…
BETWEEN extliml AND extlimu
[INCLUDING GAPS].
…
ENDPROVIDE.
Lo primero en lo que nos debemos fijar es tanto en el inicio, cómo en el final de la sentencia: PROVIDE y ENDPROVIDE. Esto nos indica que es una sentencia iterativa, es decir, que se ejecutará una y otra vez en función a las particiones dentro de los intervalos que se encuentren. Para dar una mejor explicación, vamos a construir un ejemplo sencillo de cómo podemos hacer uso de la sentencia, después lo extrapolaremos al campo de RRHH.
Tenemos dos tablas internas (lt_1 y lt_2), con cuatro campos cada una (f1, f2, f3 y f4), que contienen los siguientes datos:
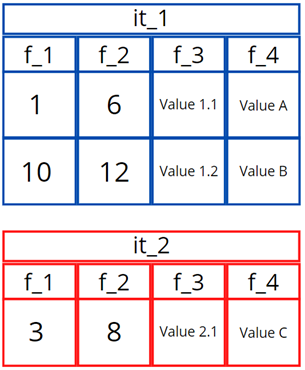
Imagen 1: Tablas de datos
Como podemos observar, los campos f_1 y f_2 de ambas tablas hacen referencia a campos numéricos, los cuales pueden definir intervalos numéricos de tipo [n_1, n_2]. Poniendo los intervalos temporales de cada tabla sobre un eje temporal, se puede ver lo siguiente:
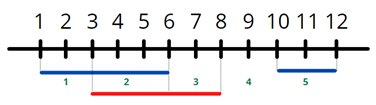
Imagen 2: intervalos temporales sobre eje temporal
Se pueden observar 5 intervalos diferenciados teniendo en cuenta los inicios y los finales de los intervalos temporales correspondientes a cada tabla. En definitiva, la sentencia PROVIDE irá cogiendo dichos intervalos uno a uno y mantendrá los datos recuperados hasta la sentencia ENDPROVIDE, donde volverá al inicio de la sentencia y cogerá el siguiente intervalo, en caso de existir, permitiéndonos meter programación entre estas dos líneas a conveniencia para tratar los intervalos como nos interese.
Vamos a desglosar la sentencia línea a línea, explicada sobre el ejemplo anterior para poder dar casos concretos de posibles entradas:
- {* | {comp1 comp2 …}}: componentes que queremos recuperar de la tabla en cada sentencia iterativa. Los campos numéricos que usemos como intervalos temporales se recuperarán por defecto, por lo que no haría falta especificarlos. Para nuestro ejemplo, los campos que nos podría interesas recuperar a parte de f_1 y f_2 serían f_3 y/o f_4.
- FROM itab INTO wa VALID flag: en itab irán cada una de las tablas que queramos procesar en la sentencia PROVIDE y en wa se recuperarán los valores de los campos que hayamos determinado en la sentencia anterior, para cada una de las iteraciones. Dichos valores los podremos recuperar para cada campo de la siguiente forma, suponiendo que hemos determinado que queremos recuperar el campo f_3 en el punto anterior: wa-f_3. En la variable flag, vendrá recogida una X en caso de que el intervalo contenga valores para una determinada iteración y vendrá vacía en caso contrario. Así, en la iteración que nos devuelve el tercer intervalo temporal de nuestro ejemplo, el flag correspondiente a la tabla it_1 vendrá vacío, mientras que el flag de la tabla it_2 será igual a ‘X’.
- BOUNDS intliml AND intlimu: en este punto se determinan los campos sobre los que se generarán los intervalos temporales que usará la sentencia para realizar los cortes. En nuestro ejemplo, intliml y entlimu serán los campos f_1 y f_2 de ambas tablas. Es importante que estos intervalos no se solapen dentro de cada tabla y que estén ordenados en orden ascendente.
- WHERE log_exp (Opcional): al igual que todas las sentencias ‘where’, podremos determinar, sobre los campos que tiene cada tabla, valores para los que se quieren o no recuperar datos.
- INCLUDING GAPS (Opcional): al añadir esta sentencia al final, incluiremos en las iteraciones los casos en los que no tengamos datos para ninguna de las tablas en los campos seleccionados. En nuestro ejemplo, haría referencia al intervalo 4.
Veamos cómo quedaría un ejemplo práctico, llevado a cabo sobre las tablas it_1 e it_2 que hemos generado. El código utilizado es el siguiente:
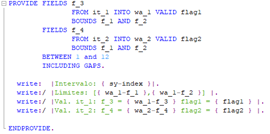
Imagen 3: código construido para realizar el ejemplo
Como podemos observar, lo que vamos a tratar de conseguir en cada una de las iteraciones serán los campos f_3 de la tabla it_1 y f_4 de la tabla it_2. Además, veremos cómo se informan las variables flag1 y flag2 en función a los valores que toman dichos campos. Los resultados son los siguientes:

Imagen 4: resultados del código
El número de intervalo se corresponde con los números marcados en verde en la imagen 2 y, analizandolos con detenimiento, podremos observar que los intervalos no se solapan y los valores de los límites se redondean al siguiente número entero más cercano que quede dentro del intervalo. Así, el intervalo 1, en la imagen 2 se podría interpretar como [1,3], no obstante el 3 se entenderá que es el inicio del siguiente intervalo y se redondeará el final de éste a 2, quedando [1,2]. Veremos cómo en el caso de RRHH esto no supone un problema, si no una gran ventaja a la hora de trabajar con los datos, ya que los intervalos se construyen con días, en vez de con números enteros.
Una vez que hemos entendido el funcionamiento de la sentencia, vamos a ver la utilidad y aplicabilidad que tiene en RRHH. En HCM se hace uso de los infotipos, los cuales conllevan fechas que determinan la validez para cada uno de ellos. Ahora bien, supongamos que queremos realizar un programa en el que se recoge información de varios infotipos, solapados entre sí. Nos puede interesar tratar la información de forma ordenada, desde una fecha incial, hasta una fecha final y con distinciones entre todos los posibles cortes que se generan solapando todos los infotipos (similar a la imagen 2). Para ello, podríamos cargar los datos de los infotipos en tablas y usar dichas tablas en la sentencia PROVIDE. A su vez, los intervalos vendrían determinados por lapsos temporales correspondientes con los campos f_1 y f_2 de las tablas de nuestro ejemplo.
Como ya hemos adelantado, los cortes que realiza la sentencia redondeando el intervalo no supondrán un problema. Vamos a dar un ejemplo para que sea más sencillo de explicar: supongamos que en nuestras tablas de ejemplo, el valor de los campos f_1 y f_2 de la tabla it_1 son 20.09.2021 y 25.09.2021. Si se determina que, el primer corte va de 20.09.2021 hasta 23.09.2021 y el siguiente desde 24.09.2021 hasta 25.09.2021, no vamos a perder información entre los días 23.09.2021 y 24.09.2021. Esto se debe a que el día 23.09.2021 al completo viene recogido en el primer intervalo y sus valores correspondientes también serán tratados y así pasará con el día 24.09.2021, cuyos valores serán tratados dentro del siguiente intervalo.
Si quieres profundizar en cómo aplicar PROVIDE en tus desarrollos o necesitas apoyo especializado en SAP HCM, contáctanos y te ayudaremos a llevar tus procesos al siguiente nivel.
Más información:
Quizas te pueda interesar

Creación de un Switch
a partir de una Business Function
En el presente artículo comentaremos la creación de un “Switch” para un paquete determinado. El objetivo de este Switch será la de controlar la visibilidad de diferentes objetos del repositorio a modo de conmutador. Este Switch está directamente asociado al paquete...

Asesorías al día
Control horario sin complicaciones para ti y tus clientes
¿Eres una asesoría y tus clientes te están preguntando por el registro de la jornada? Te ponemos al día y te damos una solución ágil, sencilla y rápida de implementar El Registro Diario de la Jornada Laboras sigue siendo uno de los puntos donde más incumplimientos se...

Creación de un selection ID
para una clase de report
En ocasiones, con el uso de base de datos lógicas podemos encontrar problemas de rendimiento dependiendo de la lógica que tengamos que implementar. En primer lugar, intentaremos solucionar esta serie de errores haciendo hincapié en el propio código. Esta serie de...