
Anteriormente vimos la primera herramienta propia de SAP para desarrollar proyectos de análisis predictivo: SAP Predictive Analytics. Siendo esta la primera herramienta creada por SAP para la realización de estudios completos de predicción.
Como ya sabemos, SAP le ha dado otra vuelta de tuerca a la analítica y dentro de la SAP Business Technology Platform (SAP BTP) se ha sustituido esta herramienta por la SAP Data Intelligence Cloud. Además de ello, hoy en día hemos visto como en cada nueva versión de SAP Analytics Cloud se han ido incorporando y mejorando las funcionalidades predictivas.
Entre las similitudes de estas herramientas, podemos encontrarnos las librerías PAL; Predictive Analysis Library que son una serie de funciones que contienen algoritmos analíticos: Clustering, Classification, Regression, etc. Y, en caso de ser necesario, podremos incluir nuestros propios algoritmos R permitiéndonos usar toda la potencia contenida en los algoritmos propios de R llegando a utilizar algoritmos y métodos que no están definidos en las librerías propias de HANA.
Es por ello que en este artículo nos centraremos en la integración de R con HANA.
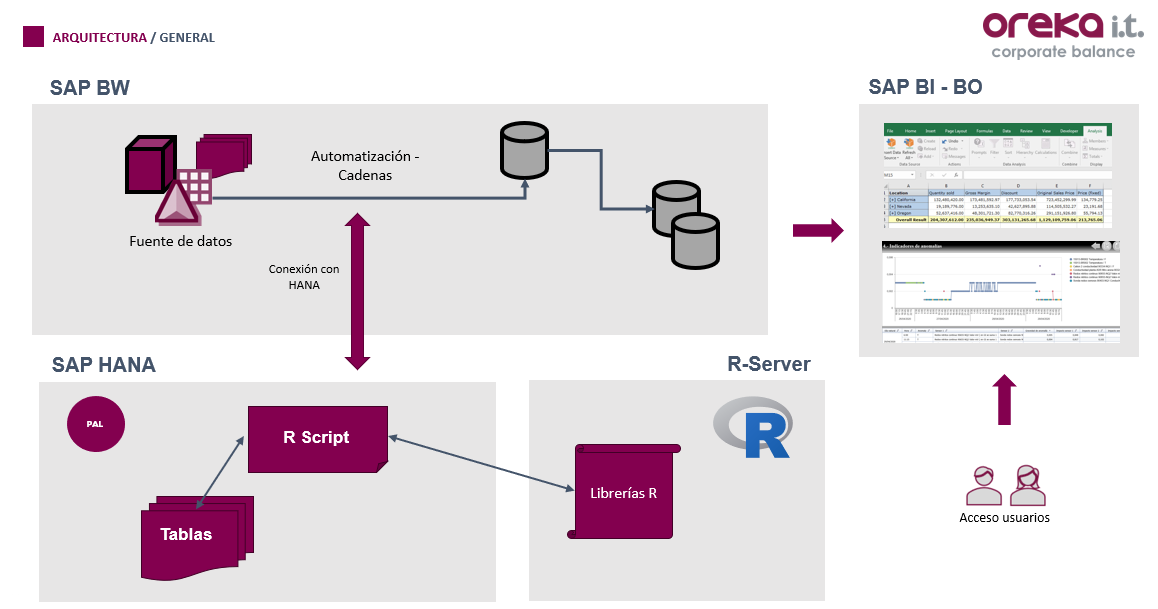
Partiendo de SAP BW como centro neurálgico de la información transmitiremos los conjuntos de datos necesarios a R a través de HANA y los resultados de R serán devueltos a BW volviendo a entrar en el flujo de la información para poder ser consumidos después desde un Afo, Lumira, SAC, etc.
¿Qué es R y cómo incorporarlo a HANA?
R es un lenguaje de programación y entorno de software libre orientado a la computación estadística. R forma parte de un proyecto colaborativo y abierto. Además, cuenta con unas funcionalidades estadísticas y gráficas básicas, permitiendo la instalación de librerías generadas por cualquier persona que permiten extender esas funcionalidades básicas para adaptarse a cualquier proyecto de Big data, Analítica avanzada o Data mining actuales.
Una vez instalado R y la librería RServe en un servidor diferente al de la base de datos HANA habrá que seguir unos pasos básicos de configuración que no son objeto de análisis de este artículo y que podrán encontrarse en la guía de integración de R con HANA: configurar propiedades de SAP HANA, dar permisos, autenticación y muchas cosas más.
Finalizada toda la configuración, para procesar código R desde la base de datos de HANA, habrá que embeber el código en un Procedure de HANA SQL declarando el lenguaje a utilizar como “RLANG”. Una vez creado un nuevo Procedure se abrirá un nuevo SQLScript en HANA que traerá predefinido el lenguaje “SQLSCRIPT” y que habrá que sustituir por “RLANG”:
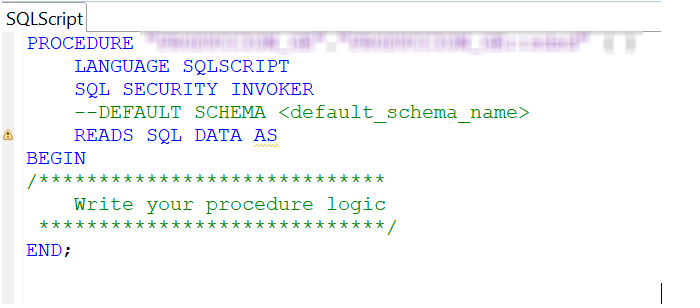
Una vez realizado ese cambio, ya se podrá escribir el código R y las declaraciones de las librerías propias de R entre las sentencias “BEGIN” y “END”.
A estos procedures R se le darán de entrada conjuntos de datos mediante una o más entradas “in” y nos podrá devolver el resultado en una o más tablas “out”.
Conexión con BW
Estos procedures se crean en HANA y podrían ejecutarse únicamente desde HANA, pero desde la llegada de SAP BW 7.4 SP5 on HANA existen en BW unos nuevos objetos que nos permitirán usar scripts predefinidos en HANA o propios para el análisis de los datos.
En lo que aquí nos atañe, al crear uno de estos procesos estableceremos un origen de datos que puede ser una tabla, AODS y un destino como pueden ser un ODS de ED o una tabla de base de datos. Pero, además, en estos objetos podremos indicarle qué script o procedure almacenado en SAP HANA se querrá ejecutar en su interior.
Estos objetos podrán incluirse en nuestras cadenas de procesos habituales, logrando así una integración completa de los scripts R a los procesos de ETL de BW: ya sea para complementar nuestro flujo con estadísticos descriptivos como para entrenar modelos predictivos y obtener predicciones automatizadas.
Esperamos que este artículo te haya sido de utilidad. Si tienes alguna pregunta no dudes en dejarla en los comentarios o ponerte en contacto con nosotros.
Más información:
Quizas te pueda interesar

De BW a BDC: evolución sin ruptura
mediante BW Private Cloud Edition
Durante los últimos años, el discurso en torno a la analítica SAP ha sido claro: el futuro será Cloud o no será. Nuevas arquitecturas, nuevos paradigmas y una apuesta decidida por la innovación. El mensaje parecía unánime: el futuro es Cloud, romper con lo viejo y...

¿Y después de NetWeaver?
Evolucionando BW y PO hacia Datasphere e Integration Suite
Fechas relevantes – La cuenta atrás ha comenzado El reloj no se detiene para los sistemas "legacy" de SAP. La fecha clave que toda empresa debe tener marcada en rojo en su calendario es el 31 de diciembre de 2027. En este momento finaliza el mantenimiento principal...

SAP BW:transición a una nueva era del dato
sin perder lo que ya funciona
El punto de inflexión en la analítica SAP Durante años, SAP BW ha sido la base sobre la que muchas organizaciones han construido su analítica. Sin embargo, el contexto actual está marcando un punto de inflexión. Las nuevas necesidades del negocio, junto con la...